
Briefly introduce to everyone how the voice changes text. I hope this introduction will be accessible to all students.
First, we know that sound is actually a wave. Common mp3, wmv and other formats are compressed formats, which must be converted into uncompressed pure waveform files, such as Windows PCM files, also known as wav files. In addition to a file header stored in the wav file, it is a point of the sound waveform. The figure below is an example of a waveform.
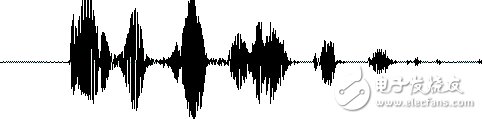
Before starting speech recognition, it is sometimes necessary to cut off the mute at the end and end to reduce the interference caused by the subsequent steps. This silent cut operation is generally referred to as VAD and requires some techniques for signal processing.
To analyze the sound, you need to frame the sound, that is, cut the sound into a short segment, each segment is called a frame. The framing operation is generally not a simple cut, but is implemented using a moving window function, which is not detailed here. Frames and frames generally overlap, as shown below:
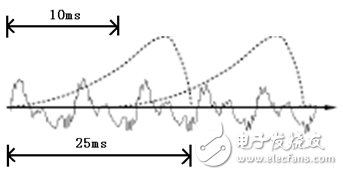
In the figure, each frame has a length of 25 milliseconds with an overlap of 25-10 = 15 milliseconds between every two frames. We call it a frame length of 25 ms and a frame shift of 10 ms. In the figure, each frame has a length of 25 milliseconds with an overlap of 25-10 = 15 milliseconds between every two frames. We call it a frame length of 25 ms and a frame shift of 10 ms.
After framing, the voice becomes a lot of small segments. However, the waveform has almost no descriptive power in the time domain, so the waveform must be transformed. A common transformation method is to extract the MFCC features and transform each frame waveform into a multi-dimensional vector according to the physiological characteristics of the human ear. It can be simply understood that this vector contains the content information of the frame speech. This process is called acoustic feature extraction. In practice, there are many details in this step, and the acoustic features are not limited to MFCC, which is not mentioned here.
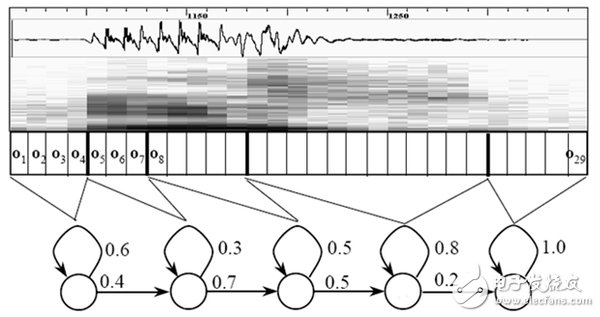
At this point, the sound becomes a 12-line (assuming the acoustic feature is 12-dimensional), a matrix of N columns, called the observation sequence, where N is the total number of frames. The observation sequence is shown in the figure below. In the figure, each frame is represented by a 12-dimensional vector. The color depth of the color block indicates the size of the vector value.
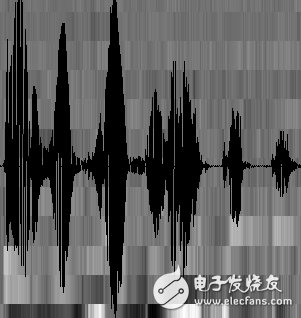
Next, we will introduce how to turn this matrix into text. First introduce two concepts:
1. Phoneme: The pronunciation of a word consists of phonemes. For English, a commonly used phoneme set is a set of 39 phonemes from Carnegie Mellon University, see The CMU Pronouncing DicTIonary. Chinese generally uses all initials and finals as phoneme sets. In addition, Chinese recognition is also divided into a tonelessness, which is not detailed.
2. Status: This is understood as a finer speech unit than a phoneme. Usually a phoneme is divided into 3 states.
How does speech recognition work? In fact, it is not mysterious at all, nothing more than:
The first step is to identify the frame as a state (difficult point);
The second step is to combine the states into phonemes;
The third step is to combine the phonemes into words.
As shown below:
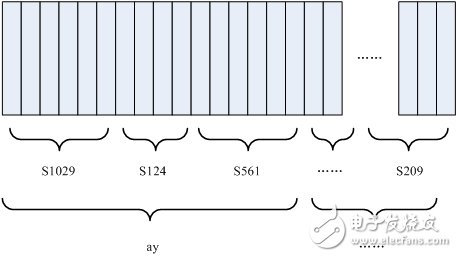
In the figure, each small vertical bar represents one frame, and several frame speeches correspond to one state, and each three states are combined into one phoneme, and several phonemes are combined into one word. In other words, as long as you know which state each voice corresponds to, the result of voice recognition comes out. In the figure, each small vertical bar represents one frame, and several frame speeches correspond to one state, and each three states are combined into one phoneme, and several phonemes are combined into one word. In other words, as long as you know which state each voice corresponds to, the result of voice recognition comes out.
Which state does each phoneme correspond to? There is an easy way to think about which state has the highest probability of a frame, and which state the frame belongs to. For example, the following diagram, this frame has the highest probability of corresponding to the S3 state, so let this frame belong to the S3 state.
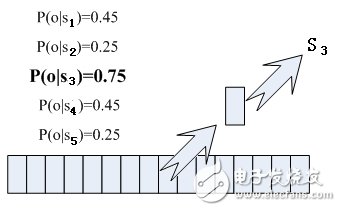
Where do the probabilities used are read from? There is a thing called "acoustic model", which contains a lot of parameters, through which you can know the probability of the frame and state. The method of obtaining this large number of parameters is called "training", which requires a huge amount of voice data, and the training method is rather cumbersome.
But there is a problem with this: each frame will get a status number, and finally the entire voice will get a bunch of state numbers, the status numbers between the two adjacent frames are basically the same. Suppose the voice has 1000 frames, each frame corresponds to 1 state, and every 3 states are combined into one phoneme, then it will probably be combined into 300 phonemes, but this voice does not have so many phonemes at all. If you do this, the resulting status numbers may not be combined into phonemes at all. In fact, the state of adjacent frames should be mostly the same, because each frame is short.
A common way to solve this problem is to use the Hidden Markov Model (HMM). This thing sounds like a very deep look, in fact it is very simple to use:
The first step is to build a state network.
The second step is to find the path that best matches the sound from the state network.
This limits the results to a pre-set network, avoiding the problems just mentioned, and of course, it also brings a limitation. For example, the network you set only contains "days sunny" and "today rain". The state path of the sentence, then no matter what you say, the result of the recognition must be one of the two sentences.
Then what if you want to recognize any text? Make this network big enough to include any text path. But the bigger the network, the harder it is to achieve better recognition accuracy. Therefore, according to the needs of the actual task, the network size and structure should be reasonably selected.
Building a state network is a word-level network that is developed into a phoneme network and then expanded into a state network. The speech recognition process is actually searching for an optimal path in the state network. The probability that the voice corresponds to this path is the largest. This is called "decoding". The path search algorithm is a dynamic plan pruning algorithm called Viterbi algorithm for finding the global optimal path.
The cumulative probability mentioned here consists of three parts, namely:
Probability of observation: probability of each frame and each state
Transition Probability: The probability that each state will transition to itself or to the next state
Language probability: probability obtained according to the law of linguistic statistics
Among them, the first two probabilities are obtained from the acoustic model, and the last probability is obtained from the language model. The language model is trained using a large amount of text, and can use the statistical laws of a language itself to help improve the recognition accuracy. The language model is very important. If you don't use the language model, when the state network is large, the results are basically a mess.
This basically completes the speech recognition process.
The above is the traditional HMM-based speech recognition. In fact, the meaning of HMM is by no means as simple as "there is nothing more than a state network." The above text is just for everyone to understand and not to pursue rigor.
Meet safety requirement such as GB31241, UL1642, IEC62133 etc; Targeted R&D, support customization. high safety battery, rechargable battery, li battery, quick charge battery, high capacity battery, ultra thin battery, steel cylilndrical battery.
A lithium polymer battery, or more correctly lithium-ion polymer battery is a rechargeable battery of lithium-ion technology using a polymer electrolyte instead of a liquid electrolyte. High conductivity semisolid (gel) polymers form this electrolyte.
12V Lipo Battery,Lithium Ion Polymer Battery,Lithium Polymer Rechargeable Battery,1800Mah Lithium Polymer Batteries
Shenzhen Glida Electronics Co., Ltd. , https://www.szglida.com